


Part 2 of 3 · RDP AI Infrastructure Series
In Part 1 of this series, we made the case for why Indian enterprises are repatriating AI workloads from cloud to on-prem. This post is about how to actually do it — without overbuilding, underbuilding, or designing yourself into a corner.
An AI factory is not a single product. It’s a stack: compute, networking, storage, power, cooling, software, and the people who run it. Get the architecture right and the deployment compounds for five years. Get it wrong and you end up with a very expensive rack that trains one model per quarter.
Here’s how we think about it at RDP — the questions we walk every customer through, and the decisions that tend to matter most.
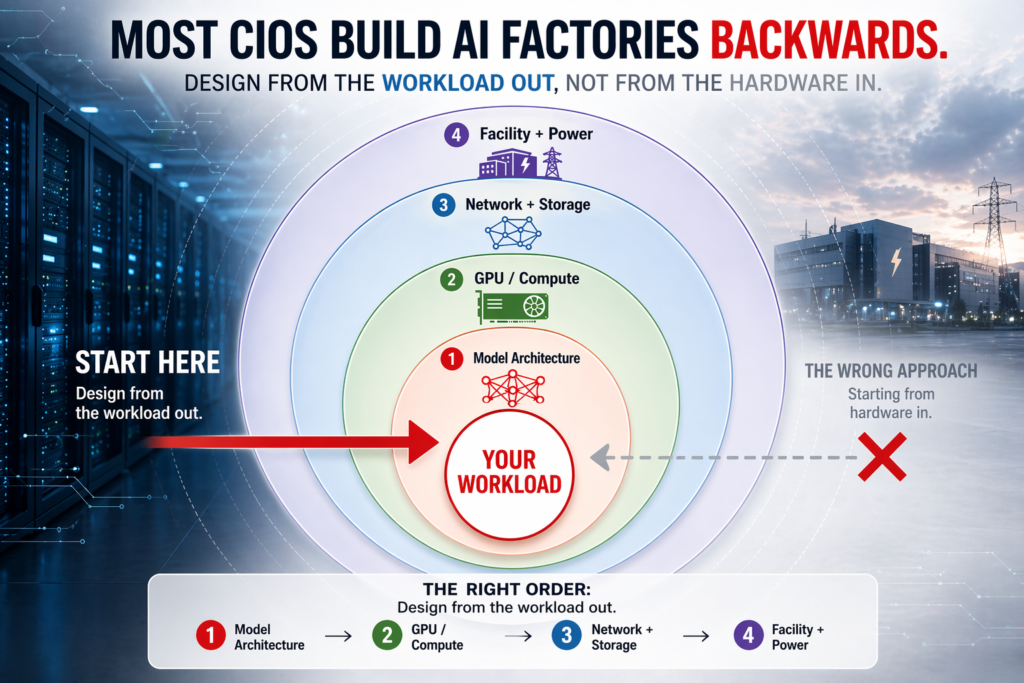
Start with the Workload, Not the Hardware
The single most common mistake we see: organizations start by asking “how many H100s do we need?”
Wrong question. Start with the workload.
There are three broad workload shapes, and each wants a different architecture:
Inference-dominant. You’re running trained models in production — a chatbot, a document classifier, a fraud detector, a RAG pipeline over corporate data. The GPU is usually one of the smaller SKUs (L40S, H100 PCIe, or even A100 for cost-optimized inference). You need throughput, low latency, and high uptime. Networking is less critical — inference workloads rarely need RDMA-class fabrics. Storage is moderate.
Fine-tuning-dominant. You’re taking open-weight or commercial base models and adapting them to your data. Think LoRA and QLoRA on Llama, Mistral, or domain-specific models. You need a mid-size GPU cluster (4–16 H100-class), fast local NVMe, and good-but-not-extreme networking. This is the sweet spot for most Indian mid-enterprise deployments.
Pre-training or large-scale training. You’re building foundation models from scratch, or doing full fine-tunes at meaningful scale. This needs real infrastructure — 32 to 128+ GPUs, 400Gb/s InfiniBand or equivalent, liquid cooling, shared parallel file systems. This is AI Factory territory in the true sense, and it’s where the top of the Indian market — banks, telcos, research institutions, and sovereign AI initiatives — is investing.
The honest truth: 85% of Indian enterprise deployments are inference-plus-fine-tuning. Very few need pre-training infrastructure. Don’t buy for the glamour workload; buy for the workload you actually run.

The Five Decisions That Matter
Once you know your workload shape, there are five architectural decisions that drive everything else. Get these right and the rest is execution.
1. GPU SKU and count
The hardware conversation has narrowed. For Indian enterprises in 2026, the practical choices are:
- L40S / L4 — inference and light fine-tuning. Cost-effective. Air-cooled. Good fit for departmental deployments.
- H100 (SXM or PCIe) — the workhorse. Fine-tuning, production inference at scale, mid-size training. SXM variants need liquid or hybrid cooling above 4 GPUs per node.
- H200 — higher memory bandwidth and capacity than H100. Increasingly the default for fine-tuning and larger inference models. Same thermal envelope considerations as H100.
- B200 / Blackwell-class — top-of-line for large-scale training. Needs liquid cooling. Lead times and procurement complexity are non-trivial; only go here if the workload demands it.
The count question is answered by your workload mix. A good starting heuristic: size for your 75th-percentile workload, not your peak. The peak is what cloud burst is for.
2. Networking fabric
This is where “AI factory” diverges from “GPU server with a lot of GPUs.” If your training jobs span multiple nodes, your fabric matters more than your GPUs. Options:
- Ethernet with RoCE (100/200/400 GbE) — good for most mid-size deployments. Lower cost, easier operations, compatible with existing data center skills. This is where most Indian enterprises land.
- InfiniBand (HDR / NDR) — required for tightly-coupled large-scale training. Higher cost, specialized skills, but the performance difference at 32+ GPUs is material.
Don’t over-spec here. A 16-GPU cluster running fine-tuning jobs is rarely bottlenecked on fabric.
3. Cooling
Indian ambient temperatures make this a first-class decision, not an afterthought. Three regimes:
- Air cooling — viable up to ~30 kW per rack. Works for edge and smaller departmental deployments. Requires good hot-aisle/cold-aisle discipline and adequate CRAC capacity.
- Rear-door heat exchangers (RDHx) — bridges to ~45–55 kW per rack. Good middle path. Relatively low facility disruption. RDP deploys these often for customers who want rack-scale without going full liquid.
- Direct liquid cooling (DLC) — required for densest H100 SXM, H200, and B200 deployments. 70–120+ kW per rack. Needs facility water loops and CDU infrastructure. Plan for 6–12 weeks of facility work if you’re retrofitting.
4. Storage architecture
Two tiers, both matter:
- Hot / scratch — local NVMe on compute nodes, or an all-flash parallel file system (Weka, VAST, DDN, Lustre, BeeGFS). This is where training datasets live during a run.
- Warm / corpus — object storage (MinIO, Ceph, or commercial) for the broader training corpus, checkpoints, model artifacts, and logs. Cheap, dense, network-attached.
The ratio that matters: for fine-tuning workloads, plan ~2–5 TB of hot NVMe per GPU. For pre-training, more.
5. Software stack
The hardware conversation is the easy part. The software stack is where operational burden lives.
- Orchestration — Kubernetes with GPU operator and a scheduler that understands GPU topology (Volcano, Kueue). Slurm remains popular for HPC-style workloads.
- Observability — Prometheus + Grafana + DCGM exporter for GPU telemetry. Log aggregation (Loki, ELK). Alerting for thermal, utilization, and failure events.
- Model serving — Triton, vLLM, TGI, or an MLOps platform that wraps one of them. Pick based on your team’s preference; the platforms are maturing fast.
- Security — perimeter, identity, data-at-rest encryption, and increasingly, model-level access controls. Treat the AI factory like any production system that handles sensitive data, because it does.
Phasing: Don’t Build It All at Once
The second most common mistake: buying the full three-year footprint upfront.
Here’s the phased approach we recommend:
Phase 1 (Months 0–3) — Pilot pod. Stand up a small cluster (4–8 GPUs, air-cooled, single rack). Objectives: prove the workload, validate the software stack, build internal skills, capture baseline metrics. Capex in the ₹60 lakh – ₹1.2 crore range.
Phase 2 (Months 3–9) — Production departmental. Scale to 16–32 GPUs. Introduce RDHx or early liquid cooling if needed. Promote pilot workloads to production. Start migrating the heaviest cloud inference workloads on-prem. Capex scales to ₹2–4 crore cumulative.
Phase 3 (Months 9–24) — Rack-scale AI factory. Multi-rack, liquid-cooled, parallel file system, proper fabric. This is the inflection from “we have GPUs” to “we operate an AI factory.” Only go here if utilization and roadmap justify it. Capex ₹6–15 crore+ depending on scale.
Each phase makes the next one easier to justify. And crucially, each phase produces real business value — not just a benchmark number.
Pitfalls to Avoid
From our deployments across Indian enterprises, the recurring failure modes:
Buying GPUs before fixing power and cooling. Hardware arrives; facility can’t support it; rack sits at 40% density for six months. Always qualify power and cooling first.
Ignoring network fabric until it bottlenecks. A well-specced GPU cluster on a mediocre fabric is a mediocre AI factory. If your workload needs multi-node training, design fabric into Phase 1, not Phase 3.
Underestimating storage. Training workloads generate checkpoints. Many of them. A 70B parameter fine-tune can produce terabytes of checkpoint data per run. Plan accordingly.
Treating it as an IT project instead of a platform. The AI factory will be used by data scientists, ML engineers, and application developers — not just the infra team. Self-service access, quotas, chargeback, and good developer ergonomics matter from day one.
Skimping on observability. When a training run silently degrades at 3 AM on day six, you’ll want metrics. Build the telemetry stack before you need it.
The India-Specific Considerations
Three things that shift the calculus for Indian enterprises specifically:
Power. Quality and cost. Tier-1 metros have decent grid quality; tier-2 often doesn’t. Plan for redundant power, UPS capacity sized for GPU workloads (not office IT), and if relevant, diesel backup with adequate runway. Your power design needs to survive the grid, not just augment it.
Facility lead times. Building out a new rack row with proper cooling in India typically runs 8–16 weeks. Longer if you’re retrofitting a space that wasn’t designed for 40+ kW per rack. Factor this into your roadmap — it’s often the critical path.
Local support and spares. Imported hardware means imported RMAs and imported spares. The difference between 4-hour on-site and 4-week-by-sea matters enormously around year three. India-based manufacturers and integrators compress this to hours, not weeks — which is a design consideration, not a sales pitch.
Where RDP Fits
This playbook is deliberately vendor-neutral — the architecture choices apply regardless of who builds your hardware. That said, if you’re evaluating partners: RDP designs and manufactures AI infrastructure in India, from edge compute to rack-scale AI factories. We ship the AI-POD for departmental deployments and rack-scale AI Factory configurations for larger installs, with India-based engineering, warranty, and support.
We tend to get engaged at two points: when an organization is pricing their first serious GPU deployment and wants a second opinion on sizing, or when they’re mid-way through a phased rollout and need a partner who can scale with them through Phase 3. We’re happy to do either. Reliability is Our Product.

What’s Next
This was Part 2 of the RDP AI Infrastructure Series — the tactical how.
In Part 3, we’ll cover the why it matters beyond cost: how Indian enterprises and government bodies are thinking about sovereign AI as a strategic imperative — data sovereignty, model sovereignty, hardware sovereignty, and the policy landscape shaping it.
Missed Part 1? Read The Real Cost of Cloud AI: Why Indian Enterprises Are Moving GPU Workloads On-Prem in 2026.
If you’re starting to scope an AI factory and want a second opinion on sizing, architecture, or phasing — speak with our AI Infrastructure team. No sales pitch, just an honest design review.
Read the full series
- Part 1: The Real Cost of Cloud AI — why Indian enterprises are moving GPU workloads on-prem.
- Part 2: Building Your AI Factory in India (you are here)
- Part 3: Sovereign AI Starts with Sovereign Compute — the policy and sovereignty angle.
Table: AI Factory Architecture Tiers — GPU Count, Power, Cooling, Space, and Indicative Budget
| Tier | Use Case | GPU Count (indicative) | Power Draw | Cooling Requirement | Floor Space | Indicative ₹ Budget |
|---|---|---|---|---|---|---|
| Tier 1 — Edge Inference | Branch / factory floor inference, IoT | 1–4 GPUs (e.g., RTX 4000 class) | 300–800 W | Standard AC; no special infra | 1–2 rack units | ₹8–25 lakh per node |
| Tier 2 — Departmental AI | Team-level LLM serving, RAG, fine-tuning PoC | 8–16 GPUs (e.g., H100 SXM or A100) | 10–25 kW | Precision AC or in-row cooling | 1–2 racks (~10 sq m) | ₹3–8 cr |
| Tier 3 — Enterprise AI Cluster | Production LLM serving, multi-model, MLOps pipeline | 64–256 GPUs | 100–400 kW | Chilled water or rear-door heat exchanger | 50–200 sq m | ₹25–100 cr |
| Tier 4 — Hyperscale AI Training | Foundation model training, national AI missions | 1,000+ GPUs (H100/B200 class) | 1–10 MW | Direct liquid cooling (DLC) mandatory | 500+ sq m dedicated DC hall | ₹300 cr+ |
RDP Technologies Limited designs, manufactures, and supports AI infrastructure — from edge compute to rack-scale AI factories — for Indian enterprises, government bodies, and research institutions. Make in India. Built for an AI-Ready India. Reliability is Our Product.