


Part 3 of 3 · RDP AI Infrastructure Series
“Sovereign AI” is one of those phrases that risks becoming a slogan faster than it becomes a strategy. It’s appeared in ministerial speeches, investor decks, and vendor brochures — often meaning four different things in the same paragraph.
Let’s be precise about what it actually means, and why it matters for Indian enterprises, government bodies, and the wider ecosystem.
This is Part 3 of our AI Infrastructure series. In Part 1, we covered the economic case for repatriating AI workloads from cloud to on-prem. In Part 2, we walked through the architecture of an AI Factory. This post is about the third leg of the stool: sovereignty — why it’s a strategic imperative, what it requires, and where the compute layer fits.

The Four Layers of AI Sovereignty
Sovereignty in AI isn’t one thing. It’s at least four distinct layers, and a well-built strategy addresses all of them:
1. Data sovereignty. Where does your training data live? Where does your inference data live at the moment it’s processed? What jurisdiction’s laws govern it? Under the Digital Personal Data Protection Act (DPDP) and sectoral mandates from the RBI, IRDAI, and MeitY, Indian enterprises are increasingly required to keep sensitive data — and the processing that touches it — within India. Cloud regions labeled “Mumbai” or “Hyderabad” help, but don’t fully resolve questions of parent-company access, foreign subpoena, or cross-border support personnel.
2. Model sovereignty. Do you control the model weights, or do you rent them? A vendor’s API is a dependency. An open-weight model you’ve fine-tuned on your data and deployed on your infrastructure is an asset. The gap becomes existential if the vendor changes pricing, deprecates the model, or restricts access — all of which have happened in the past eighteen months across the major frontier labs.
3. Hardware sovereignty. Where is your compute physically located, who manufactured it, and what’s the supply chain behind it? For most enterprises, hardware sovereignty isn’t about building your own chips — that’s a national-scale conversation. It’s about whether your AI infrastructure can be serviced, expanded, and replaced within India, with reasonable lead times, by teams you can actually reach.
4. Stack sovereignty. The software layer — orchestration, serving, observability, security — is increasingly where lock-in hides. Open-source foundations (Kubernetes, PyTorch, vLLM, Triton, Prometheus) give you stack sovereignty by default; proprietary platforms give you convenience at the cost of portability. Neither is wrong. Both are choices.
Enterprises and government bodies in India need to make conscious decisions at each of these layers. “We’re running our AI in the cloud” answers none of these questions; it defers all four.
Why 2026 Is the Policy Inflection Point
Three converging forces have moved sovereign AI from an aspirational topic to an operational one:
The DPDP Act is in force. Data fiduciaries now have concrete obligations about where personal data is stored and processed, and who can access it. The enforcement regime is nascent, but the compliance obligations are not. For any enterprise processing customer data through an AI model, the question “where does that inference happen?” has moved from architectural curiosity to legal requirement.
The IndiaAI Mission is actively deploying capital. With ₹10,000+ crore committed to indigenous AI compute, a National AI Compute Facility being built out, and sector-specific AI initiatives in health, agriculture, and education — the public sector is signalling that domestic AI infrastructure is strategic, not optional. Procurement mechanisms under BIS and PLI frameworks are tilting the field toward Make-in-India hardware.
Sectoral regulators are specific now. RBI guidance on cloud and AI usage in financial services, IRDAI’s position on insurer data handling, MeitY’s procurement preferences for government and government-adjacent deployments — each reduces the ambiguity about where sensitive workloads should run. For BFSI, insurance, healthcare, and public sector buyers, sovereign deployment paths aren’t a philosophical preference; they’re a compliance fit.
The point isn’t that cloud is disallowed. It isn’t. It’s that the default assumption — “run it in the cloud unless there’s a reason not to” — has inverted. For sensitive workloads in regulated sectors, the question is now “what’s the reason to run this outside the country?”
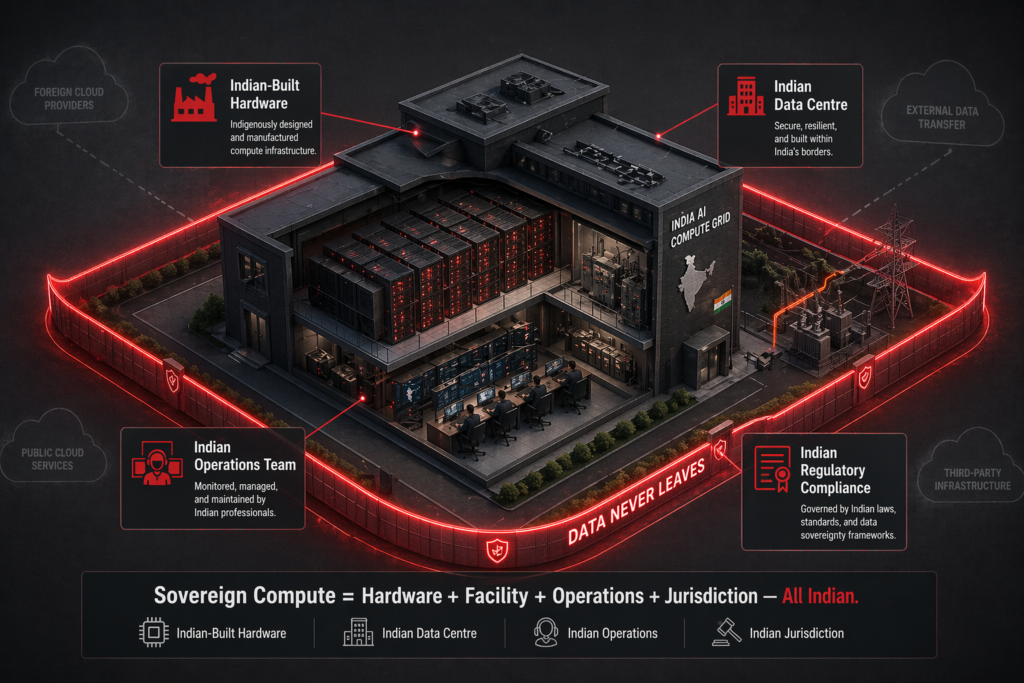
What “Sovereign Compute” Actually Looks Like
When we talk about sovereign compute at the infrastructure layer, we mean three concrete things:
Physical presence. The GPUs, storage, and networking running your workload are in a data center inside India — ideally one you control or have a clear contractual line of sight into. For government-adjacent workloads, this usually means an on-prem deployment or a dedicated facility; for commercial enterprises, it increasingly means owned or co-located infrastructure rather than multi-tenant cloud.
Supply chain legibility. You know who manufactured the system, who supports it, and where replacement parts come from. For critical infrastructure, opacity in the supply chain is itself a risk. Make-in-India hardware — hardware designed, integrated, and supported by Indian companies — collapses the distance and the ambiguity.
Operational autonomy. You can run the system without depending on an external party’s permission, uptime, or pricing discipline. This doesn’t mean no vendors; it means no single vendor whose failure takes you offline. Software open-source by default, hardware supportable by multiple partners, data never one API call away from being inaccessible.
None of these three requires monk-like purity. Hybrid architectures are fine. Vendor partnerships are fine. The question is where the core sits — and whether, in a crisis, you’re waiting on your own team or someone else’s.
The Economic Alignment
One of the quiet pleasures of the sovereignty conversation is that it aligns with the economic case we made in Part 1.
Sovereign compute — properly designed — is usually cheaper over a 3–5 year horizon than the cloud alternative, as we showed in the TCO analysis. That’s not a coincidence. The hyperscaler premium built into USD-denominated GPU-hours reflects capital cost, margin, and FX — none of which scale in your favor. Build domestically and you capture the efficiency.
So the decision tree for many Indian enterprises now looks like:
- Regulated workload with sensitive data? Sovereign on-prem or domestic colo. Compliance and economics both align.
- Inference-heavy production workload at scale? On-prem or hybrid. Economics dominate.
- Experimental workload with low utilization? Cloud is fine. Sovereignty cost doesn’t make sense yet.
- Burst capacity for training spikes? Cloud, wrapped around a sovereign core. Best of both.
This is not a binary choice. It’s a portfolio.
Where Indian Industry Fits In
There’s a broader question beneath the enterprise conversation: does India have an AI infrastructure ecosystem capable of supporting sovereign deployment at scale?
Honest answer: it’s forming, and faster than most people realize.
Indian system integrators are building real AI infrastructure practices — no longer just reselling imported boxes, but designing, integrating, and supporting rack-scale deployments.
Indian hardware manufacturers — including RDP — are shipping AI infrastructure across edge, departmental, and rack-scale tiers. Make-in-India isn’t symbolic anymore; it’s a supply chain that exists.
Indian colocation and data center operators have been building AI-ready facilities — liquid-cooling-capable, high-density power, tier-III+ certified — across Mumbai, Hyderabad, Chennai, Bangalore, and increasingly NCR and Pune.
Indian talent — ML engineers, data scientists, infra engineers — is abundant. The operational capability to run a modern AI stack is not the constraint.
What’s still gapping: the dense upstream supply chain (silicon, HBM, advanced packaging) sits outside India. That’s a national-industrial-policy conversation, not an enterprise one. The IndiaAI Mission and adjacent semiconductor initiatives are the right conversations; they don’t affect your 2026 deployment.
For 2026 purposes: the ecosystem to build sovereign AI infrastructure inside India exists, is actively growing, and is increasingly the preferred path for regulated sectors.
The RDP Position
We build in India for Indian customers. Our AI infrastructure portfolio — edge compute, AI-POD for departmental deployments, rack-scale AI Factory — is designed, manufactured, and supported domestically. That’s not a marketing angle. It’s a structural choice that shows up in lead times (weeks, not months), warranty response (hours, not days), and long-term parts availability (years, not “while supplies last”).
For customers navigating sovereign AI — BFSI, public sector, telecom, research institutions, large enterprises with regulated data — the combination of Indian manufacturing, Indian engineering, and Indian support removes several sources of risk that imported alternatives carry silently.
We’re also explicit about what we don’t do: we don’t pretend that every workload needs to be sovereign, and we don’t push on-prem where cloud is a sensible fit. The calculus depends on workload shape, regulatory posture, utilization, and three-year trajectory — which is exactly the conversation Parts 1 and 2 of this series are about.
Reliability is Our Product.

Closing the Series
Across three posts, we’ve argued:
- Part 1 — the economics of cloud AI have broken under production workloads. On-prem is 40–60% cheaper over a 3-year horizon for workloads above 40% utilization.
- Part 2 — building an AI factory is a workload-first, phased, five-decision exercise. Start small, prove value, scale deliberately.
- Part 3 — sovereignty is a four-layer conversation (data, model, hardware, stack), aligned with economics, and increasingly compulsory under Indian regulation.
The through-line: Indian enterprises in 2026 have real, economically rational, regulatorily aligned reasons to bring AI infrastructure in-house and in-country. It’s not a nationalism argument. It’s a strategy argument.
If you’re navigating any of these decisions — pricing out your first deployment, scoping an AI factory, or thinking through what sovereign AI means for your organization — speak with our AI Infrastructure team. We do honest technical assessments, not sales calls.
Read the full series:
- Part 1: The Real Cost of Cloud AI — why Indian enterprises are moving GPU workloads on-prem.
- Part 2: Building Your AI Factory in India — a CIO’s playbook for 2026.
- Part 3: Sovereign AI Starts with Sovereign Compute (you are here).
Table: Sovereign AI vs Hyperscaler AI — What India Gives Up
| Dimension | Sovereign / On-Prem AI (Indian-controlled) | Hyperscaler AI (AWS / Azure / GCP) |
|---|---|---|
| Data Residency | Data physically within Indian jurisdiction at all times | Logical residency claimed; physical location depends on provider’s architecture |
| Regulatory Control | Full — DPDP, SEBI, RBI, MeitY requirements met natively | Shared responsibility model; compliance audits require vendor cooperation |
| Inference Latency | 1–10 ms on local fabric | 15–80 ms via public internet + shared GPU pools |
| CapEx vs OpEx | High upfront CapEx (₹3 cr+ for meaningful cluster); predictable thereafter | Zero CapEx; OpEx scales with usage — can exceed CapEx TCO in 2–3 years at scale |
| Vendor Lock-in | Hardware portable; software stack fully open (PyTorch, vLLM, etc.) | Proprietary APIs, SDKs, and model formats create migration friction |
| Fine-Tuning Freedom | Full access: RLHF, QLoRA, full fine-tune on any dataset | Restricted — provider controls what can be fine-tuned and on what data |
RDP Technologies Limited designs, manufactures, and supports AI infrastructure — from edge compute to rack-scale AI factories — for Indian enterprises, government bodies, and research institutions. Make in India. Built for an AI-Ready India. Reliability is Our Product.